Yet another 5 practices of CI for WebApp’s deployment


Hello, reader! In this article, I want to collect for myself the best practices of deployment that I found useful. Some of them are widely used, some I have not encountered in the wild and invented by myself. I hope this article will be useful for you as well, as it’s not often you get to show the inner workings of projects — here’s your chance!
In this article, I am not insisting on the singularity of these practices; everything has its shortcomings.
So, Practice #1: Create an infrastructure project and use submodules.
Git has the ability to create nested projects. I find this super useful, especially when projects become more complex — when you deepen their structure. First, you have a small Python web application, which you debug locally and bring to some condition. Then you need to manage the database directly from the admin page, and you have two projects. This means that there is already a specific relationship between them — someone has to run them. An infrastructure project appears in the group of projects.
It also allows you to tune CI once, only in an infrastructure project. The resulting structure is as follows:
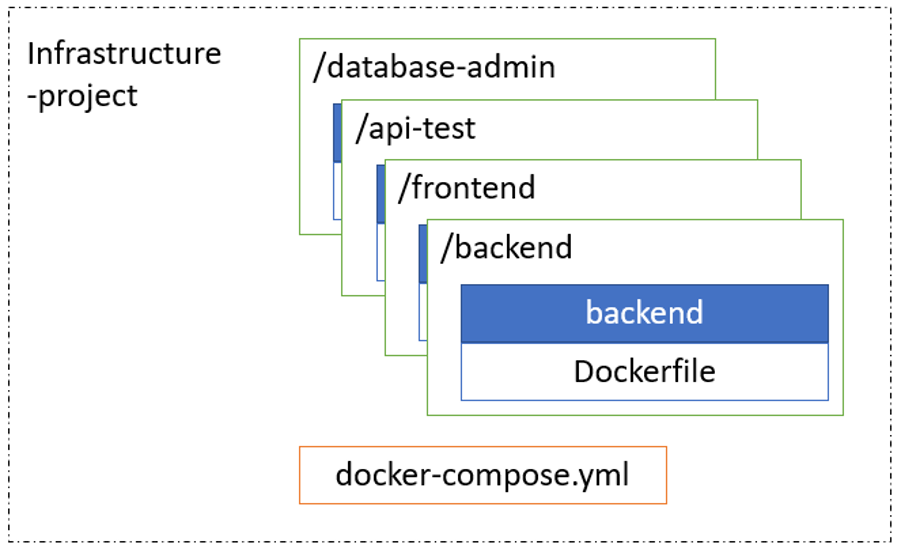
Practice #2. Update your submodules with CI.
It’s common for developers and testers to not be super cool with the infrastructural intricacies — make their life easier for them, make a button! Usually, one person is in charge of the submodule, and another person on the team organizes the rollout. Create an update trigger in a submodule, for example, in the frontend submodule. Then add a job in the yaml to the infrastructure project, as in the example.
For submodule project:
#.gitlab-ci.yml for submodule (frontend example)
stages:
- upd-submodule
variables:
GIT_STRATEGY: clone
.update:
stage: upd-submodule
variables:
SUBMODULE_PATH: 'frontend/${CI_PROJECT_NAME}'
SUBMODULE_NAME: '${CI_PROJECT_NAME}'
SUBMODULE_BRANCH: '${CI_COMMIT_BRANCH}'
SUBMODULE_SHA: '${CI_COMMIT_SHA}'
UPDATE_SUBMODULE: 'true'
trigger:
branch: '${TARGET_BRANCH}'
project: web_site/site-cluster
strategy: depend
when: manual
update-master:
variables:
TARGET_BRANCH: master
extends:
- .updateAnd for infrastructure project:
#.gitlab-ci.yml for infrastructure project
update:submodule:
stage: pre-build
rules:
- if: $UPDATE_SUBMODULE == "true"
tags:
- linux
before_script:
- git config --global user.name "${GITLAB_USER_NAME}"
- git config --global user.email "${GITLAB_USER_EMAIL}"
script:
- echo "Updating ${SUBMODULE_NAME} to ${SUBMODULE_SHA} of ${SUBMODULE_BRANCH} branch..."
- cd ${SUBMODULE_PATH}
- git pull origin ${SUBMODULE_BRANCH}
- git checkout ${SUBMODULE_SHA}
- cd ..
- git add ${SUBMODULE_NAME}
- git commit -m "upd ${SUBMODULE_NAME}"
- git push https://root:$ACCESS_TOKEN@$CI_SERVER_HOST:$CI_SERVER_PORT/$CI_PROJECT_PATH.git HEAD:${CI_COMMIT_REF_NAME}It remains to define the ACCESS_TOKEN from “Settings”>”Access Tokens” to “Settings”>”CI/CD”>”Variables".
Practice #3. Use workflows to implement multiple pipelines in one project.
I assume that even without submodule updates, your CI has a lot to do. Well, then use workflows or mimic them.
A. Create a separate yaml for updates because you don’t need it in the main pipeline.
B. Define a variable only with the definition of which the update pipeline will be active.
C. Separate the rules. If you use self-hosted GitLab > 14.2, add rules to include the following scheme:
# main .gitlab-ci.yml
include:
- local: .gitlab-ci-main.yml
rules:
- if: $UPDATE_SUBMODULE != "true"
- local: .gitlab-ci-subs.yml
rules:
- if: $UPDATE_SUBMODULE == "true"If not, add rules to every job definition.
If the pipeline assumes a specific commit name, use a regular expression. If it assumes a specific event, such as push, use $CI_PIPELINE_SOURCE.
Practice #4. From git submodule to production in one click by modifying autocreated pipelines.
Using practices 1–3 described earlier, we’ve come very close to running a configurable pipeline: update the submodule, run the build, test it, and send it to production. This is made possible by using the properties of the “git push -o” command and the rules together. As an example, I’ll take the last line of practice #2 and add this, where TRIGGER_SUBMODULE variable is the name of the build job:
-o ci.variable="TRIGGER_SUBMODULE=${SUBMODULE_NAME}:build"And add this to it to make the following:
git push https://root:$ACCESS_TOKEN@$CI_SERVER_HOST:$CI_SERVER_PORT/$CI_PROJECT_PATH.git HEAD:${CI_COMMIT_REF_NAME} -o ci.variable="TRIGGER_SUBMODULE=${SUBMODULE_NAME}:build"For the job that we want to trigger, we will automatically write rules.
rules:
- if: $UPDATE_SUBMODULE == "true"
when: never
- if: $CI_JOB_NAME == $TRIGGER_SUBMODULE
when: always
- when: manualNB: The new pipeline will run on behalf of the Access token, so it must have the appropriate permissions: either it must be a group token (req. GitLab>14.7) or create a user with the right permissions and replace root:$ACCESS_TOKEN with user credentials.
The voice of one crying in the wilderness: I will take this opportunity to say what I miss about Gitlab is the options for autocomplete variables at startup. So, for example, now you have to remember which variables and what values are important and what values they can take. Having the ability to choose from several options would make it possible to run pipelines more finely. But at least part of the choice of variables can be transferred to the cases described in this practice #4.
Practice #5. Meeting CI and Docker by tagging and environment substitution.
A hike in which images are tagged from CI has proven to be a good idea. This can be either the branch name or the SHA commit, or both at once.
docker build -t $GC_IMAGE_NAME:$CI_COMMIT_REF_NAME -t $GC_IMAGE_NAME:$CI_COMMIT_SHAIt is convenient to manage them in the cloud repository and look for errors. If you need a multi-step build, these tags can be used with the envsubst tool. For example, if two dependent images are built in one pipeline, it is sufficient to refer to the SHA commit tag in the second one and use
envsubst < Dockerfile | tee Dockerfile_step2This handy tool helps not only with CI variables but also with modifying files from demo to production, just like the Helm charts for Kubernetes is often used.
Concept. Use GitLab as Documentation.
This also goes into the CI centric approach to documentation — better than writing a lot in the wiki, automate it in CI “click the button, you get the result,” and most importantly, it is immediately clear how to repeat it by hand.
Practices are being refined and new ones mastered, so I hope the article will have a sequel.