What are the Video Codecs?

A small article about how the video codecs work and why this technology is so important for the modern media industry.
Background: the intent of this article was born out of a discussion with my friends about media software: how it works and why it’s important. After that, I understood that what’s really needed is a short, simple article about it. So here I’ve explained why we need codecs and presented an overview of how they work.

So many codec names
AVC, VP8, VP9, HEVC and modern AV1, VVC — what are all these? And why so many of them?
All these abbreviations are different codecs. They could be divided into two groups:
· Royalty codecs (ITU/MPEG): AVC ->HEVC -> VVC
· Open source/royalty free: VP8 -> VP9 -> AV1
The comparison of codecs is a large topic for another article, but here I’ll just share some key facts:
· Current popular codecs are AVC (H.264) and VP9 (used in many popular streaming services, WebRTC, YouTube, Twitch)
· HEVC (H.265) is a great technology drafted in 2013. In spite of its efficiency, HEVC is poorly adopted due to uncertain and non-FRAND (Fair, Reasonable and Non-Discriminatory) licensing terms.
· AV1 is a modern and royalty free codec. The first stable release happened on the 28th March 2018. It is actively adopted in popular streaming services on YouTube, Netflix, etc.
· VVC (H.266) is a successor to HEVC. It was approved in July 2020 and is expected to be the most advanced compression technology among others.
As you can see, there is a variety of co-existing codec standards, all of them continuously evolving and competing..
Why Codecs Were Developed
First of all, we have to understand why we need codecs:
If we turn on our video camera to record a typical two-hour film without any compression, we will have an RGB file. Let’s calculate its size:
Given parameters:
· Length of the film: 2 hours
· Frames per second: 30
· Resolution: 1920x1080
· Color format: RGB
2 * 3600 * 30 * 1920 * 1080 * 3 = 1343692800000 bytes
Or 1.22 TB! How many TBs does the HDD in your computer have…?
Whereas if we use HEVC to compress the movie in question, we can reduce its size down to around 2.5GB — that’s 500 times smaller! And that’s without changing the resolution or the frame rate, and without any dramatic reduction in quality.
Problem identified. How Can We Fix It?
Ok, I hope you see the problem: raw streams are very, very large. And they will only get bigger due to increasing resolution, frame rates, length, effects (like HDR) and so on.
So, we need some compression technologies, but what can we do? We know from basic theory that there are two types of compression:
· lossless
· lossy
Plus, different color formats can be employed too.
Color formats
Bright/luma encoding (.yuv) is used in most cases instead of RGB format**.**
Why so? There is a scientific research in which the human eye is described as more sensitive to luma (brightness) than to color. So we can save some bytes per pixel. For example, a popular format of encoding is 4:2:0 (1.5 bytes per pixel) — chrominance components have half the horizontal and vertical resolution of luminance components (from the book ‘H.264 Advanced Video Compression Standard’ by Iain Richardson). Remember that this format is only for storage: when you see the film your videocard converts YUV to RGB.
Lossless compression
Let’s emulate lossless compression (and it is used, cf. VLC) and see how good an outcome we can get:
Input:
· Raw video file with YUV color format: vicue_test_1920x1080_420_8_500.yuv
· Size: 1,44 GB (1 555 200 000 bytes)
· Number of frames: 500
I use 7zip with the following settings:
· Format: 7z
· Level of compression: Medium
· Method of compression: LZMA2
· Dictionary size: 16 MB
· Size of word: 32
Output:
· vicue_test_1920x1080_420_8_500.7z
· Size: 301 MB (316 626 856 bytes)
· The compression rate is almost 5:1. Not ideal…
Conclusion: in the above example, the compression rate was good (5:1) but we can still do better.
Lossy Compression: Reference Test
How good can modern encoders compress the video file?
Let’s try to answer this question: for a useful and comparable result, we can encode the same .yuv with HEVC using ffmpeg:
ffmpeg -f rawvideo -pix_fmt yuv420p -s:v 1920x1080 -r 25 -i vicue_test_1920x1080_420_8_500.yuv -c:v libx265 output.mp4
Result:
· output.mp4
· Size: 12,5 MB (13 168 899 bytes)
· Compression ratio 118:1!
· Raw log of ffmpeg:
Input #0, rawvideo, from 'vicue_test_1920x1080_420_8_500.yuv':
Duration: 00:00:20.00, start: 0.000000, bitrate: 622080 kb/s
Stream #0:0: Video: rawvideo (I420 / 0x30323449), yuv420p, 1920x1080, 622080 kb/s, 25 tbr, 25 tbn, 25 tbc
Stream mapping:
Stream #0:0 -> #0:0 (rawvideo (native) -> hevc (libx265))
Press [q] to stop, [?] for help
x265 [info]: HEVC encoder version 3.0_Au+7-cb3e172a5f51
x265 [info]: build info [Windows][GCC 8.2.1][64 bit] 8bit+10bit
x265 [info]: using cpu capabilities: MMX2 SSE2Fast LZCNT SSSE3 SSE4.2 AVX FMA3 BMI2 AVX2
x265 [info]: Main profile, Level-4 (Main tier)
x265 [info]: Thread pool created using 8 threads
x265 [info]: Slices : 1
x265 [info]: frame threads / pool features : 3 / wpp(17 rows)
x265 [info]: Coding QT: max CU size, min CU size : 64 / 8
x265 [info]: Residual QT: max TU size, max depth : 32 / 1 inter / 1 intra
x265 [info]: ME / range / subpel / merge : hex / 57 / 2 / 2
x265 [info]: Keyframe min / max / scenecut / bias: 25 / 250 / 40 / 5.00
x265 [info]: Lookahead / bframes / badapt : 20 / 4 / 2
x265 [info]: b-pyramid / weightp / weightb : 1 / 1 / 0
x265 [info]: References / ref-limit cu / depth : 3 / on / on
x265 [info]: AQ: mode / str / qg-size / cu-tree : 2 / 1.0 / 32 / 1
x265 [info]: Rate Control / qCompress : CRF-28.0 / 0.60
x265 [info]: tools: rd=3 psy-rd=2.00 rskip signhide tmvp strong-intra-smoothing
x265 [info]: tools: lslices=6 deblock sao
Output #0, mp4, to 'output.mp4':
Metadata:
encoder : Lavf58.26.101
Stream #0:0: Video: hevc (libx265) (hev1 / 0x31766568), yuv420p, 1920x1080, q=2-31, 25 fps, 12800 tbn, 25 tbc
Metadata:
encoder : Lavc58.47.102 libx265
frame= 500 fps=5.4 q=-0.0 Lsize= 12860kB time=00:00:19.88 bitrate=5299.3kbits/s speed=0.217x
video:12854kB audio:0kB subtitle:0kB other streams:0kB global headers:2kB muxing overhead: 0.049566%
x265 [info]: frame I: 4, Avg QP:27.84 kb/s: 6871.70
x265 [info]: frame P: 456, Avg QP:30.31 kb/s: 5370.48
x265 [info]: frame B: 40, Avg QP:33.20 kb/s: 3891.26
x265 [info]: Weighted P-Frames: Y:4.8% UV:4.2%
x265 [info]: consecutive B-frames: 91.7% 7.8% 0.4% 0.0% 0.0%encoded 500 frames in 91.77s (5.45 fps), 5264.15 kb/s, Avg QP:30.52
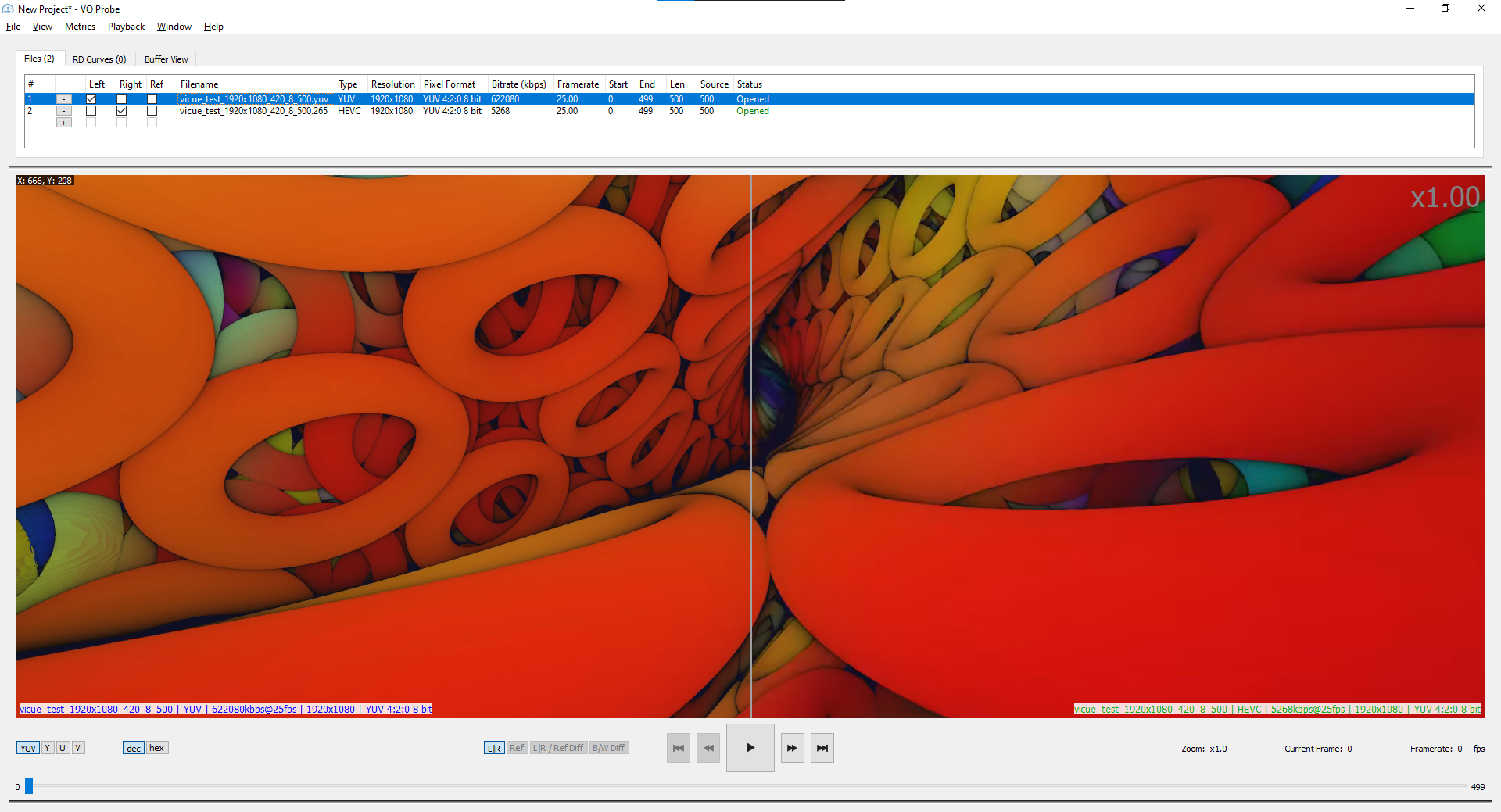
There are some small discrepancies between pictures, but visual quality looks the same while the file size is reduced to 12.5 MB. This shows the importance of codec compression technology.
Lossy compression: explanation
‘If we use lossy compression, we lose the quality.’ While this is true, there are some technologies and techniques which can help us achieve an almost (or completely) unnoticeable loss in quality.
The main techniques to save bytes are as follows:
· Similar elements in a frame can be ‘inherited’ from another place in the same frame (called intra prediction)
· The same concept of ‘inheriting’, but taking place between different frames (inter prediction)
For people who know Git VCS well the idea is the same: saving not the entire file but rather the delta (diff) of the file only.
Process of encoding
So next we can look at the diagram, which shows the high-level encoding process:
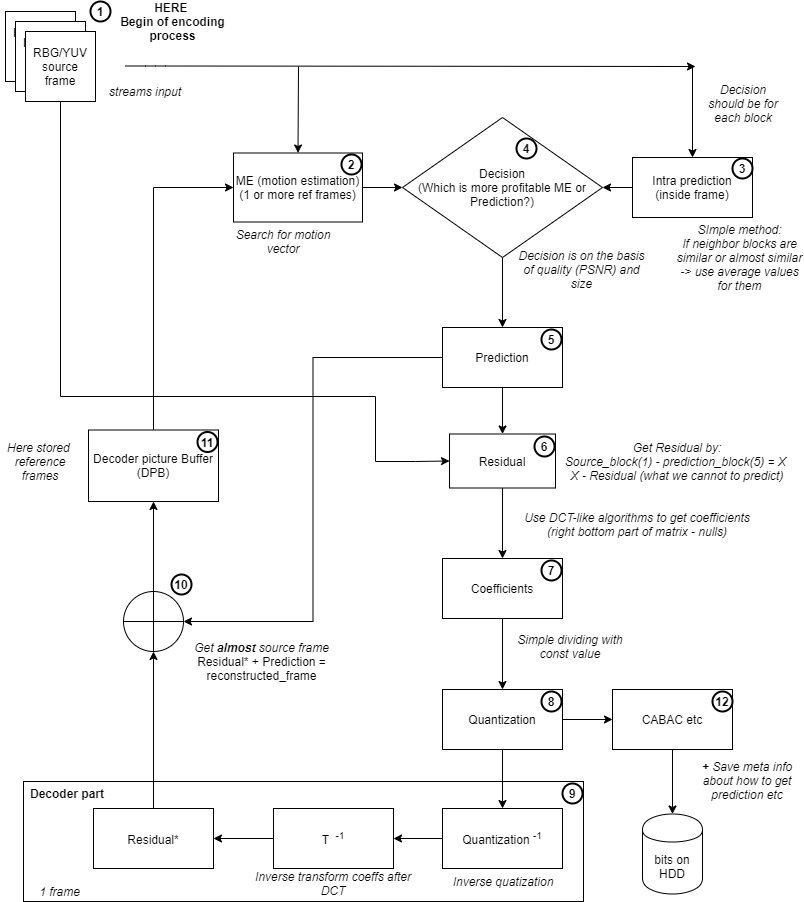
Explanation of Pic. 2 — the encoding process:
1. As the input, we have the source video file, for example with extension .yuv. To begin encoding, we take 1 frame from the video. Each frame should be divided into blocks. For each block we calculate (in parallel!):
2. [parallel] Motion estimation (ME) (inter) — the encoder searches for blocks which can be ‘inherited’ from blocks in another frame or frames
3. [parallel] Intra prediction — the encoder searches for blocks that can be ‘inherited’ from blocks within the same frame
4. After calculation of the motion estimation and intra prediction, the encoder makes a decision and chooses which prediction is more profitable (based on own criteria minimizing bits budget and maximizing quality).
5. From this step onwards, we work with predictions (not source images). In other words, prediction is the result of the process which gives us artifact with minimum residual.
6. The residual is all the data that we cannot predict. The conditional formula for residual is: source_block — prediction_block=residual_block
7. At this step our goal is to reduce residual. The encoder does it by the algorithms like DCT. The principle of DCT is to maximize the characteristics of a picture with minimal coefficients. It has strong ‘energy compaction’ properties: most of the signal information tends to be concentrated into a few low-frequency components of DCT which improves the efficiency of subsequent quantization process (it reduces loss of quality and improves compression in most cases).
Here’s a good visualization of a matrix after DCT:
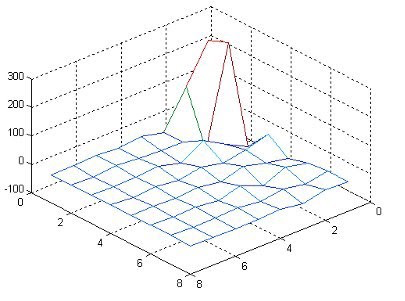
8. Quantization may be used to reduce the precision of image data after applying a transform, such as DCT, and to remove insignificant values such as near-zero DCT *(*from the book H.264 Advanced Video Compression Standard, Iain Richardson). In other words, it is a simple reduction of values: matrix_of_coefficients/matrix_of_constants. At this step, the video stream gets maximum lossy effect. Here’s a formula-example of the process
quantized_coefficient[i] = round(coefficents[i]/q_step[i])
where:
· quantized_coefficient is the vector of coefficients after quantization
· coefficents— vector of coefficients after DCT
· q_step— vector of constants (or dynamical values in modern codecs) which are part of codec specification.
9. Yeah, it is a decoder in an encoder. In each encoder there is a decoder. It is needed to predict the following frames. The frames should use predictions from the already encoded blocks (otherwise we wouldn’t benefit), so that is why the encoder needs a decoder.
10. Encoder sums: residual*(5)+prediction(9)=reconstructed_frame. As a result, encoder gets almost source frames to put them into Decoder Picture Buffer (DPB). DPB is a buffer of the fixed maximum size where the reference frames are stored which will be used for ME (step 2).
11. When the frame/block is ready, we can use entropy coding algorithms (for example CABAC).
Conclusion
As we can see, codecs are complex technologies that use a wide range of math algorithms (a modern codec like VVC even uses some elements gained from the world of machine learning). Their development is always ongoing thanks to a wide range of areas for improvement and evolving techniques. Finally, codec evolution is continuously pushed forward by the market with its increasing appetites like higher resolutions (fullhd-4k-8k-16k), 360 video, higher frame rates (30-60) and special effects (like HDR), but at the same time with smaller bandwidth cost.