Comparison of codecs on the web

Our goal is to develop a web application for codec quality comparison. Calculations for video encoding require significant resources and time. Not every user has an idle machine with enough computing power. Our application provides required utilities and resources using our tools VQ Probe and Testbot for quality comparison operations and cloud systems as computing power. This article is dedicated to describing the cloud services we have used to make it work.
Cloud assessment
Speaking of cloud systems, we needed a platform with high reliability, a wide range of features, and good documentation, so our choice was made in favor of the Google Cloud platform. It has a convenient and well-documented API, versatile services, and an extensive trial period, during which our team managed to choose the necessary technology stack, learn the basics of platform usage, make a few errors, and find the most fitting solution for our goals.
The pipeline of our project is amazingly simple: create a container with necessary parameters and programs and launch its execution in a cloud service. Google Cloud initially attracted us with the Google Cloud Run service. This service lets you deploy containerized projects that work with requests via HTTP, HTTP/2, WebSocket, or gRPC. However, after a few initial launches in Google Cloud Run, we decided to use something more powerful and more finely tuned for our tasks. Something similar to a separate machine, entirely dedicated to the task, with configurable computing resources and control over the execution of work. So we switched to Google Cloud Compute Engine as our cloud computing provider.
Structure of the project
Upon choosing the cloud platform, the project was subdivided into four parts:
- Containerized app with the running environment (Worker + Google Compute Engine)
- Database (MongoDB)
- Storage (Google Cloud Storage/Google Cloud Artifacts Registry)
- Web application (VQ Codec Test Platform)
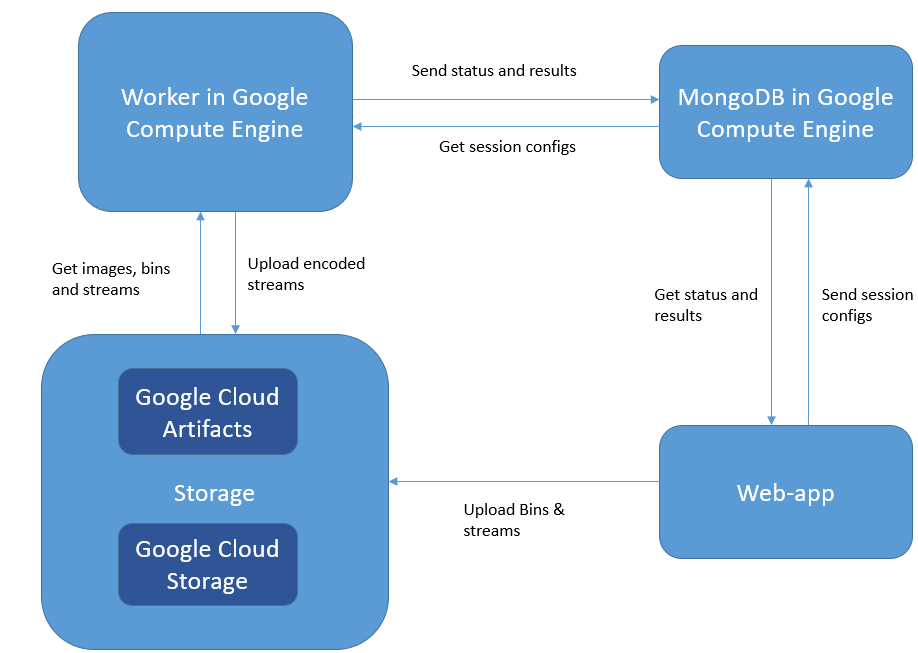
The web application is the face of the project that interacts with all other parts. The scheme takes data from the database, generates commands for the worker, uploads codecs and streams to Cloud Storage.
Upon receiving a command and configuration from the user, the web application launches workers. Each of them retrieves an image for execution from Artifacts Registry, queries the database for the parameters of the target session, and downloads the rest of the necessary data from the Cloud Storage. Cloud Storage stores standard and user-loaded stream packs and codec sets, and Artifacts Registry stores application images to run on a virtual machine. This manager privately stores our worker images and allows you to load them into Compute Engine with ease and speed since all the necessary data is combined into one system.
Configuring the machines
Each session from the web application spawns a new VM instance in the Compute Engine. Furthermore, each instance requires its own configuration file, which will tell exactly what to execute in the loaded container. The configuration carries information about the type of machine, its launch zone, the required amount of memory and metadata for the container, which are determined individually for each process.

Metadata contains the main parameters of the launched image, location of the container itself, command with arguments, and the environment variables.
One configuration parameter is also an option to run discounted unstable instances. There are two types of such instances: preemptible instances and spot instances. The significant advantage of these instances is the price - from 60 to 91% discount, but this means that your VMs can be preempted if those resources are needed elsewhere (which practically happens rarely). Both types of discounted instances have the same functionality; however, preemptible instances always stop after 24 hours of operation.
In our case, calculations either do not take too much time (or we are trying to achieve such results) or can be restarted without much data loss, so using such tools has a tremendous economic benefit for the project. When splitting session execution into multiple instances, we use spot VMs that are managed by a stable session manager running in parallel with the spot VMs.
For simple, lightweight calculations, we use the machine of ‘n1-standard-1’ type. The tables below show hourly prices for using GCE machines in the 'europe-west4’ region.
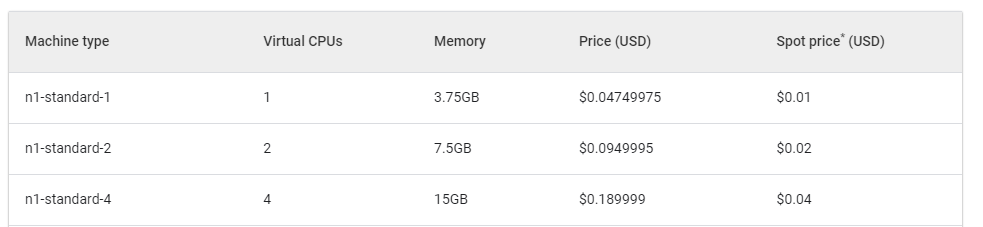
Table 1. Current standard machine prices.
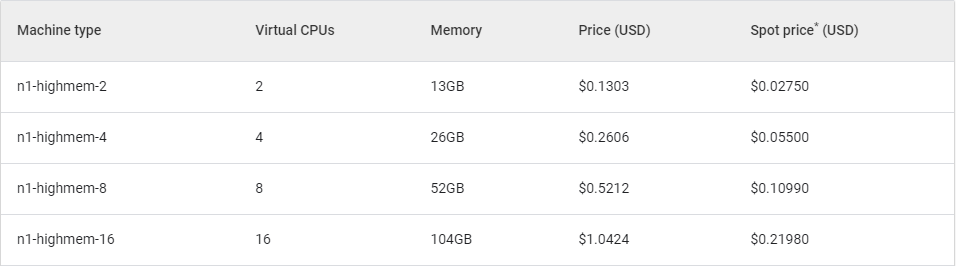
Table 2. Current prices for high memory machines.
Those prices are reevaluated daily, so our calculations are approximate. Taking a typical testing session as an example, we have four instances and one manager. This session takes around 4 to 6 minutes and short sessions have not been shut down by google once. From table 1, we can see that each stable instance costs around 0.005 $ - so 4 of them is 1.5 cents, but when using Spot instances – it takes 0.003 $ for all of them.
For a more real-world example, we ran the test on 10 HD streams with a more powerful machine. As a reference machine, we have amd3960x with 128 Gb RAM, and in GCE, we will use n1-highmem-4 machines, which have 4 CPU and 25 Gb RAM. The session on the local machine took 7.5 hours to be completed. However, using our cloud machines working in parallel on each stream takes 4.5 hours. Using ten stable machines for 4.5 hours – 12$, Spot machines – 2.5 $. Almost 80% off!
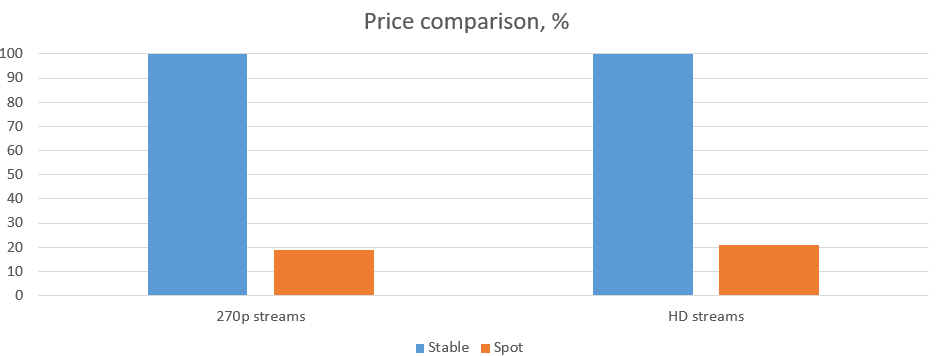
Now let us talk about failures. Looking at a series of test launches, we have had google shutting down machines once in about 3 to 4 sessions. So yeah, it happens, and if your job is highly dependent on time – you probably do not want to be greedy and hope that your session will not be affected. Use stable machines and get your result in the shortest time possible. However, spot machines are the best option for those who can wait.
To use this type of VM in the configuration file, you must use the scheduling option:

The configuration file also has a web version analog - Compute Engine Console, where all the same parameters can be set up independently using a convenient interface.
Nevertheless, since the web application cannot use the human interface, it is necessary to configure the service through the gcloud API, which connects our web application to the Google Cloud platform. Connection occurs with service accounts API. Each service account is configured for specific access to distinguish between performed tasks and ensure security.
The web application and worker interact with the Google Compute Engine using API methods. The user starts the work of the instance when creating a session, can stop or restart the working instance, and inside the session manager (you can read about the work of the manager and increasing the computing capabilities of the system in another article), the status of controlled instances is checked.
Conclusion
The journey of exploring cloud systems can sometimes seem too hard for new projects because there are many parameters and options to use and set up. Launching our project to Google Cloud took many hours of reading documentation, experimenting, and trying out ways to gain our goals, but it was possible due to an extensive knowledge base about the platform in quite a short time. Ways of launching your own application are endless, so even for us, something new is learned every day.