Analytic tools 8.0 – «The Data storage reform»

New Analytic tools version 8.0 has a lot of performance improvements to save your time when preparing coverage reports!
Innovations
What is the most valuable resource in our rapid life full of tasks to be done? Of course, it is our time. The DVK team values your time not less than its own, so the primary objectives for the Analytic tools 8.0 update were performance acceleration and usage flexibility improvements. Let's start with the major features and discuss some minor peculiarities at the end.
Leaving SQLite behind
During the entire existence of the Analytic tools, we used SQLite as the main approach to provide coverage data storing and maintenance. This direction was considered beneficial for user experience for years because of the centralized storage of data as a single file. Moreover, with the help of tools like «DB browser for SQLite», it was convenient to examine stored coverage data before the representation as such. Despite all pros, the cons became more noticeable from year to year. One of the most irritating of them was far from perfect multi-user capability, which would be really helpful in the case of implementing parallel coverage collection via multiprocessing. Moreover, SQLite handles write operations that are serialized, which also applies some limitations on concurrency. Summing it all up, we needed something simple, flexible, and with the possibly minor restrictions imposed on the implementation of parallel execution.
Beauty lies in simplicity
As a result of discussing a new possible way of data storage for the Analytic tools, our team has focused on storing coverage data as zipped files divided by the category. Sounds simple, doesn't it? That's correct!
ZIP advantages
So, what about the advantages of using zip instead of SQLite?
First of all, we have the opportunity to define the structure of cache folder where access to each coverage archive will be independent and exclusive. Thus, we need no synchronization primitives to control the access to our coverage entities, which dramatically influenced the coverage extraction acceleration as a result. Furthermore, the client would have convenient access to any file representing the coverage:
- Syntax coverage – CSV files created by a specific decoder.
- Cross coverage – json files created in addition with syntax csv if the decoder supports cross-coverage extraction.
- Code coverage – json files, which are essentially lightweight versions of Clang code coverage json files.
Last but not least, the summarized amount of memory needed to store the SQLite storage was expected to be more memory-consuming because the relational databases are focused on the maintenance of data integrity and not the compression.
Parallel coverage collection
As we have chosen a new data-storing approach and the design of caching, the path for implementing parallel execution for the collector while obtaining the best advantage in the context of time consumption was free. In previous versions, threads gave the collector acceleration in input/output operations, such as writing data to the cross-coverage files. One more advantage is the fact that the python thread is more easily killed than the process. Nevertheless, the process pool execution would give us CPU-bound acceleration, decreasing the time spent on stream decoding and several complex data transformations. Moreover, killing the spawned processes is a matter of a few lines of code.
As a result , we got zip storage of data controlled by multiple processes, which essentially don’t mess up with each other.
The results
After this major budding update, it was a great pleasure for me to collect the statistics of this new performance data, and it is even more pleasant for me to share it with you!
Time and memory consumption
As for the test data, it was decided to choose about 500 VVC streams and compare the results of the old revision of the Analytic tools and the new one. As for the mode – extraction and representation of all coverage types (syntax, cross, and code) were active. The results, in this case, were outstanding!
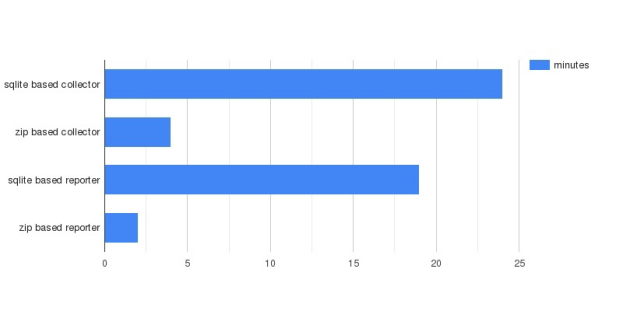
As you can see, while the old collector required a bit more than 24 minutes to extract coverage data, the new one needed less than 5 minutes to complete this task. And what about the reporter? This coverage-representing tool used to take about 18 minutes to represent the coverage for 500 streams. Now – slightly more than 2.5 minutes. It means that we have accelerated the collector 5.5 times and the reporter - 7 times, which makes sense by all means!
And what about memory consumption? The resulting picture was no less inspiring!
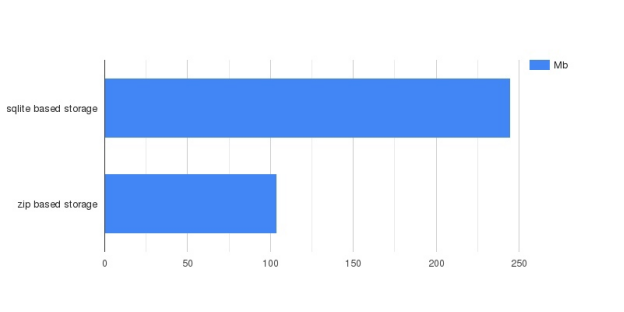
While SQLite storage required about 245 Mb of memory to store the complete set of coverage data, the zip-based storage took a bit more than 100 Mb. It means that we have reduced memory consumption on the disk 2.5 times.
Plans for the future releases
Great work was performed to make your experience with the Analytic tools more convenient and save your time wasted while waiting until the coverage report will be ready to show itself. Nonetheless, we never rest on what we have achieved. These performance improvements let the DVK team focus on the functionality improvements of the Analytic tools. The next step – make the report page more flexible and detailed in case of the coverage info. To be more precise, it would be so neat to know by what stream a particular cross-coverage element was covered…
Full changelog
Version 8.0
The caching process was reimplemented
- Cache storage moved from Sqlite to zip files storage
- [collector] collector work time was accelerated 5.5 times
- [reporter] Reporter work was accelerated 7 times
- Cache storage size reduced by 2.5 times
Parallel execution was reimplemented
- [collector] Thread-based execution was replaced by the process pool
- [collector] Any coverage data is collected without process synchronization, except the `profdata` accumulation for the code coverage.
Minor changes
- [optimizer] `--code-coverage` flag was added to enable code coverage consideration.
What are analytic tools?
The analytic tools represent a proven facility to analyze syntax and code coverage of video streams. They give maximum flexibility and can be used with DVK streams and any customer streams as well.
These tools give a graphical representation of syntax coverages, speed up the test cycles by reducing the streams and their number, compare the stream coverage.
How to get them?

You can use the latest version of analytic tools by purchasing DVK or contact us to get solely analytic tools!
Or check the available sets here.