What is dev infrastructure for beginners (part 1): understanding


Synopsis
The ideas of this article were born during my discussion with bachelor students. I understood that there are many people who do not understand how infrastructure for development works and looks. So I decided to make a try to explain as much as I can. I will start by defining the problem, principles, and "forms" of dev infrastructure so that it will be more about understanding rather than a step-by-step solution. But I will expand the topic with additional articles if I have feedback.
Why is the author allowed to comment on this topic?
My first three years in the IT industry were in the positions of infrastructure guy. I had the experience of integrating CI processes in big companies and also implementing development infrastructure from scratch in small companies. Yeah, I am not an expert with 30+ years in the industry, but I have experience and opinion. If you have additions, let's discuss them because it is a discussion wherein the truth is born.
Article structure
- Find and formulate the problem
- Automation
- Continuous Integration (CI)
- What is needed for automation?
- CI service responsibility
- Thoughts on some bottlenecks
- Bonus: DevOps
- Conclusion
Find and formulate the problem
First of all, let's find and highlight the problem because correct understanding helps to find a solution.
Number 1 — teamwork
The IT industry was all the time about working in the team. Yeah, we had some examples of dev-stars, but their software needs the community to improve, productize, and support. The community will discuss priorities, report bugs, push the code, and sometimes hate you :)
Number 2 — in fact, projects are vast and complex
See the projects like Linux kernel or Chromium. They are essential for all the internet and have hundreds of developers (not only developers but also many managers, testers?), very old, vast, and complex. Don't believe me? Let's see the stats from lwn.net about Linux kernel version 5.14 development:
To create 5.14, the kernel community applied 14,735 non-merge changesets from 1,912 developers; 261 of those developers made their first kernel contribution during this cycle. There were 861,000 lines of code added to the kernel and 321,000 lines removed, for a net growth of 540,000 lines.
Number 3 — you are not a programmer; you are a business problem solver
… your code is not the code; it is solving a business problem. From this point of view, managers and responsibility to customers "enter the stage". You, as a developer, need instruments to prove that your code fixes and improves the current product status. It would help if you had the minimum build, test, and validation systems.
To sum up
We have a lot of people who interact with each other, a vast mass of coders and managers who want some proof of your work. To solve this, we can hire more people, do all the staff manually or … implement automation!
Automation
Honestly, almost all the staff in the IT industry can be called automation because of the nature of computers. Still, I focused this article on infrastructure for development and principles, so the word automation means— Continuous Integration (CI) and some things around it.
Continuous Integration (CI)
First programmers (or very bad teams today) had a lot of “manual“ work because they didn't have so many libraries, frameworks, and tools such as we have today. God, thanks!
Thus, for example, a middle-size C++ project in the past. Developers have only some self-written bash scripts to build and test the project. They start them manually or with cron before the release or once per week. I can imagine how much pain and hell the build, start, and tests can be after another commit.
Therefore, upon analyzing this, what was the decision by these "first programmers"? Building and testing are like hell? Yeah? So let's do it much often! Every day! For every commit!
They implemented the systems that we now call CI-systems to support this practice.
More importantly, they formulated CI principles — integrate your changes to the mainline product as soon as possible.
In addition, program managers formulated a unique formula which tells us:
The sooner you find a mistake, the cheaper it is to fix it.
CI, strict definition by Wikipedia:
In software engineering, continuous integration (CI) is the practice of merging all developers' working copies to shared mainline several times a day.

Bonus:
Continuous delivery (CD) is a continuation of CI principles in the field of delivery of product updates to the customers/users. I don't want to delve deeper into this practice because we must first understand the basic principles. I will give only a strict definition from Atlassian for those who suffer:
Continuous Deployment (CD) is a software release process that uses automated testing to validate if changes to a codebase are correct and stable for immediate autonomous deployment to a production environment.
What is needed for automation?
Ok. I hope we are ready to define problems and principles for solving, but what are the "bricks" of our automation? What are the "bricks" of infrastructure for software development?
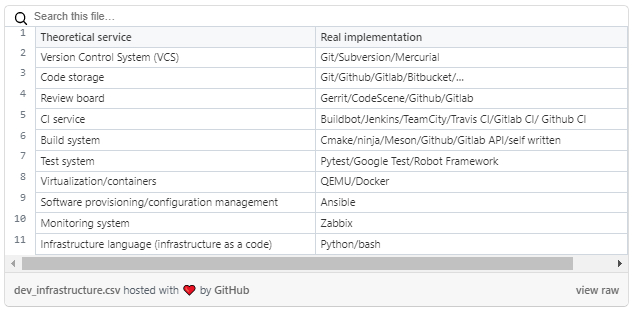
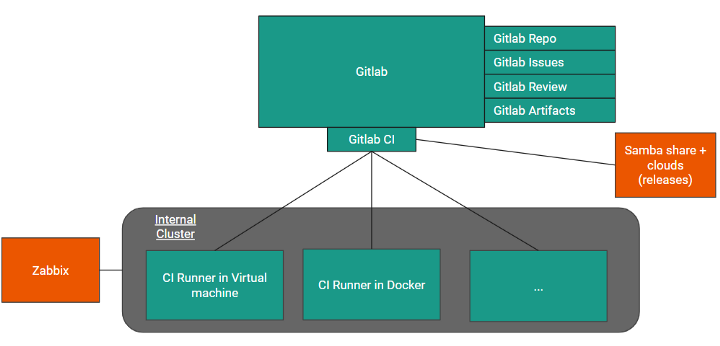
Every infrastructure architect/developer should choose the "bricks" based on the domain, company rules, product programming language, experience, costs, flexibility level, and team. There is not a "holy grail". Yeah, there are systems like Gerrit and others which are a bit legacy and not trendy. So, they have modern analogs, but in general, the architect should know the actual needs of the development team to implement the right, easily supportable, and flexible infrastructure.
CI service responsibility
From the illustrations above, we can see that in the center of infrastructure there should be "CI service," but what should this service do? I tried to formulate it, my version:
- Check changes in Version control systems (VCS)
- Take the changes from VCS
- Allocate a suitable machine (scheduler)
- Execute predefined scenario on the machine
- Log the scenario
- Report build/test status
- Upload build/test artifacts
Thoughts on some bottlenecks
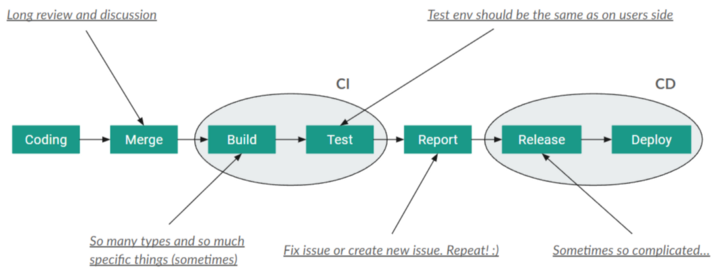
I used the same illustration but added some comments to mark that it cannot be easy. These are only a few possible issues and complications that an infrastructure guy may encounter.
If we speak about CI only, in this case the most popular example is how many builds, tests, and simple checks can be started for one regular commit? 2? 4? 10? Here is a small illustration from (not the biggest) project Intel MediaSDK:
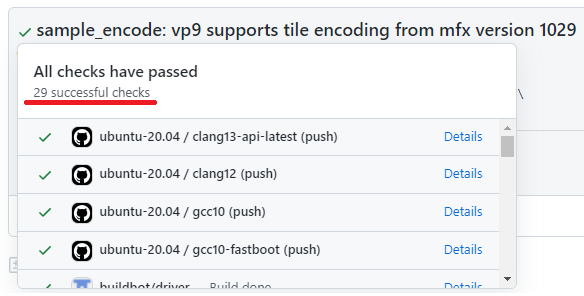
29 various checks (CI runs) started for only one commit, and all of them should be predefined, the environment for execution should be ready, and so on and so forth … I want to underline that such project is not as big as the Linux Kernel project, and we do not discuss the validation process (the process of complete testing).
Bonus: DevOps
Term DevOps deserves a separate article, but as a bonus, I will provide a strict definition and some personal comment; Wikipedia's strict definition:
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops). It aims to shorten the systems development life cycle and provide continuous delivery at high software quality.
As you see from this definition, it is all about the reduction of development time (cycles) -> as a result, become more adaptive to clients (market) -> as a result, more income.
As DevOps is intended to be a cross-functional mode of working, those who practice this methodology use different sets of tools — referred to as “toolchains” — rather than a single one:
Coding - code development and review, source code management tools, code merging.
Building - continuous integration tools, build status.
Testing - continuous testing tools that provide quick and timely feedback on business risks.
Packaging - artifact repository, application pre-deployment staging.
Releasing - change management, release approvals, release automation.
Configuring - infrastructure configuration and management.
Monitoring - applications performance monitoring, end-user experience.
DevOps destroys strict responsibility limits and says that the personnel should be cross-functional within reason. I specifically wrote "personnel" because, I think, there is a big problem when you see job offers with trendy slogans "We are looking for a DevOps expert". My opinion is that the team should be DevOps, not a particular worker. Yeah, the sysadmin must know more about the product, but I think it is rather a question of integrity and motivation.
So I think, DevOps is an excellent methodology but be careful with the term because sometimes its use is wrong.
Conclusion
In this article, we dissected problems, introduced terms with their definitions, decided on the system's structure, and marked possible bottlenecks. So we have a theoretical basis to start building infrastructure for software development.
In the following article, I will try to create a model of the actual development process and try to implement some elementary infrastructure to support this dev process.
To sum up, all the right work of infrastructure guys comes down to simple as possible operations which a rank-and-file developer should execute to push the code and close the ticket, like this:
git clone https://github.com/Intel-Media-SDK/MediaSDK.git
git checkout -b "my_super_branch"
# some changes in code
git commit -am "[cmake] Add right location for sha execution"
git push origin my_super_branch
