Decoder-Side Motion Vector Refinement (DMVR) in VVC

Welcome to a new article about Versatile Video Coding! Today we are delighted to tell you about a new VVC feature that uses motion estimation on the decoder side! For demonstration we will use VQ Analyzer — a bitstream analysis tool developed by ViCueSoft.
Although the main idea of decoder side motion derivation (DMVD) is not new — it was well studied during HEVC development — it was applied for the first time in VVC. The goal of DMVD is to avoid transmitting motion information in a bitstream by allowing the decoder to search for motion by itself.
In VVC, DMVD evolves into decoder-side motion vector refinement (DMVR). DMVR is used to increase the precision of Merge Mode prediction without additional signaling.
There are two translational motion vector prediction modes in VVC: advanced motion vector prediction (AMVP) and Merge mode. They both use motion prediction candidates from spatial or temporal neighboring blocks. In AMVP mode, this information is signaled in the bitstream: candidate index, motion vector difference and reference picture index. In Merge mode, only the best candidate index is signaled (Figure 1). That’s why Merge mode uses less bits for motion coding, but also provides less accuracy. Here, DMVR takes place to increase the precision.
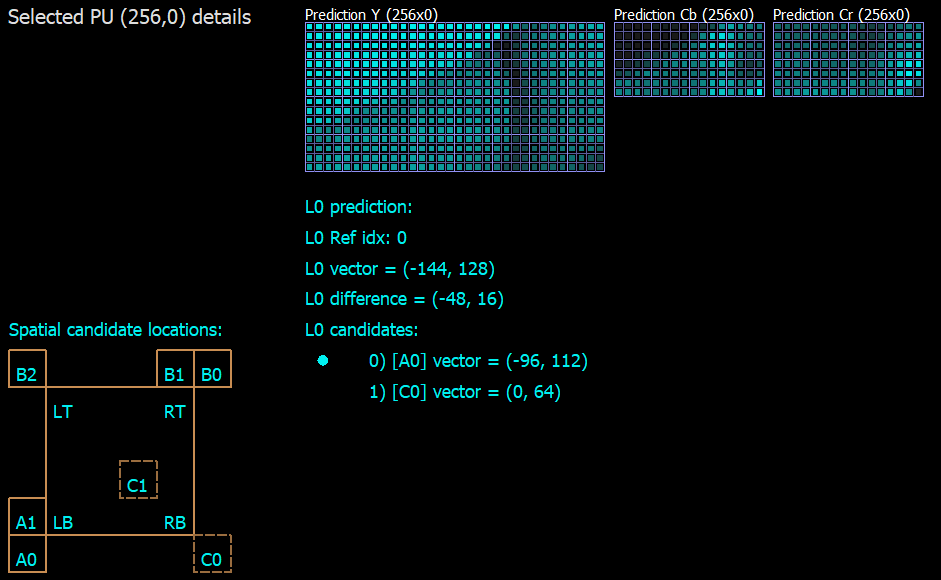
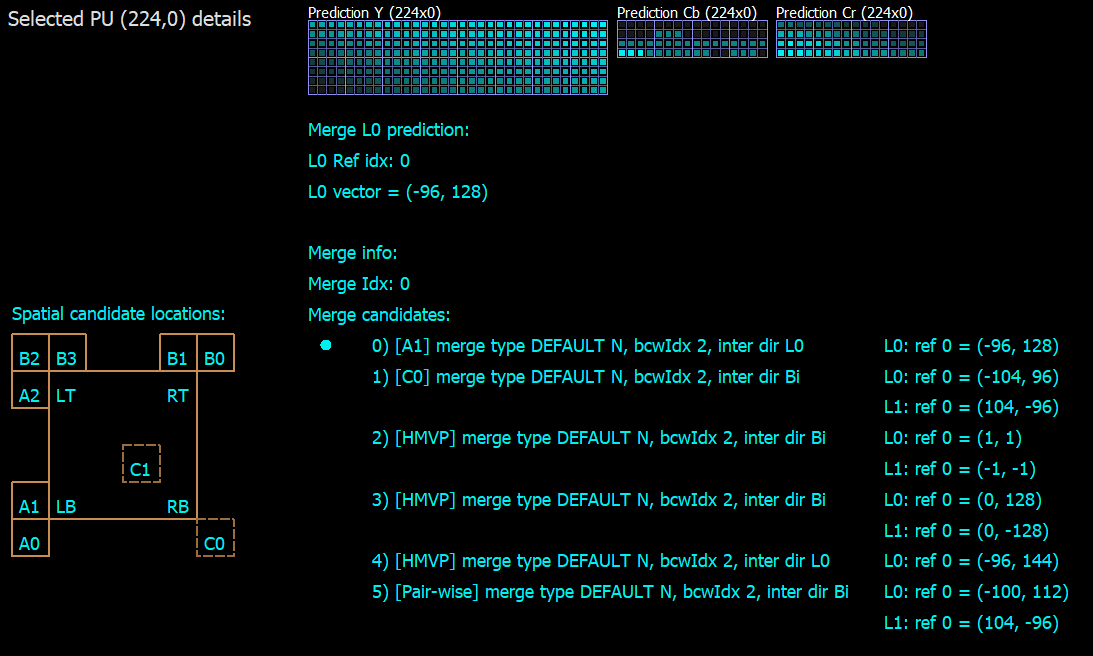
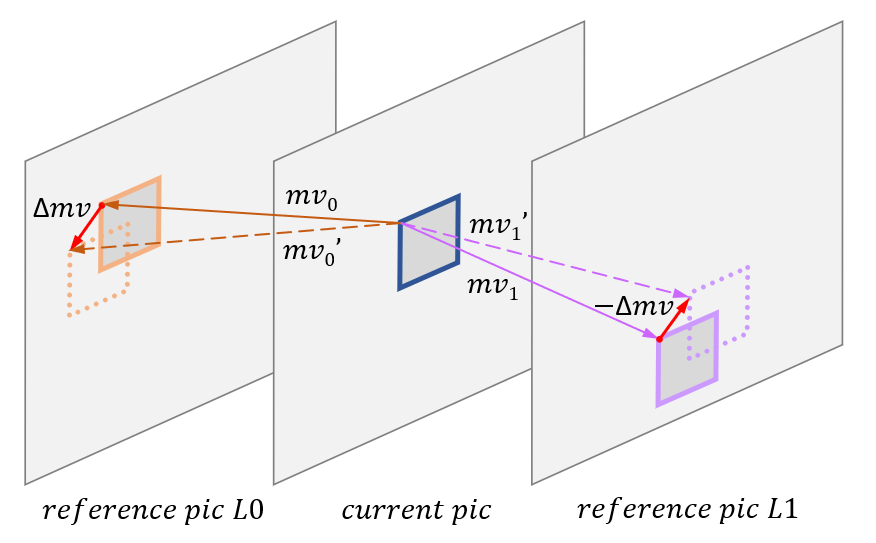
The result of DMVR is a refined motion vector. It is searched around the original MV prediction on L0 and L1 reference pictures. Search is based on calculating distortion between the L0 and L1 candidate samples (Figure 2). For simplification, the sum of absolute difference (SAD) is used as a distortion metric. Offset with lowest SAD is used for derivation of refined motion vectors.
DMVR Algorithm
VVC applies DMVR with bilateral-matching method, so it works only for bi-prediction Merge blocks. To reduce memory requirement and gain precision, the block is divided into subblocks for DMVR processing. Subblock size is up to 16x16, each subblock gets its own refinement independently.
In order to reduce computational complexity, search is divided into two stages: integer and fractional. Resulting refinement is the sum of both stages.
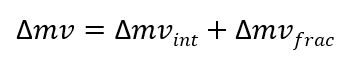
Integer search is performed by SAD comparisons, and then fractional refinement is applied by using 2d parabolic error surface.
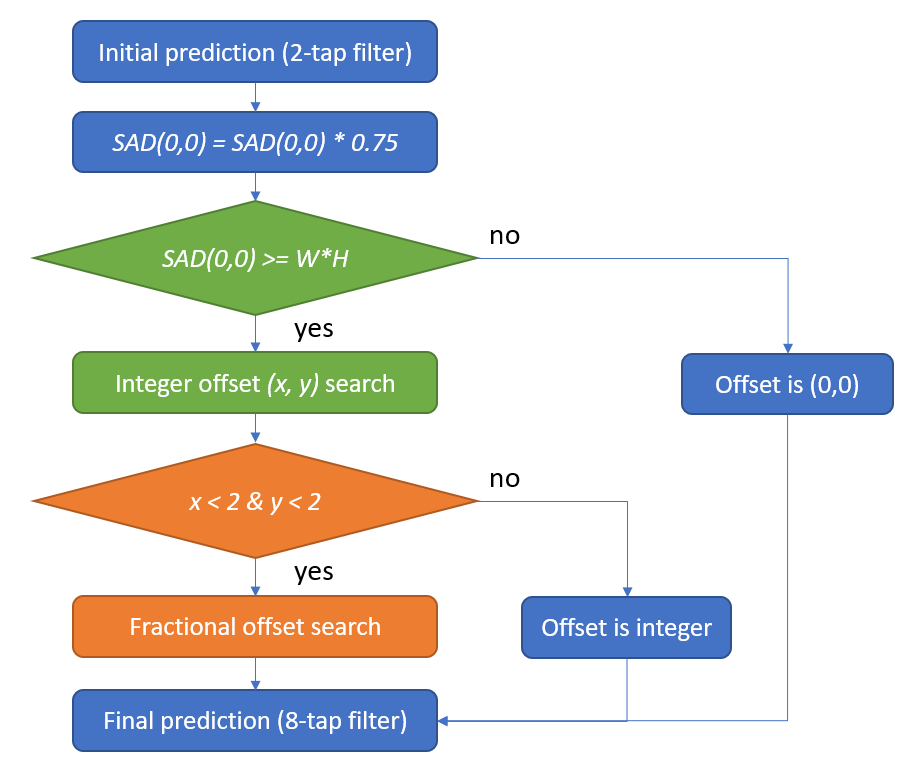
Algorithm stages applied for each subblock:
1. Initial interpolation
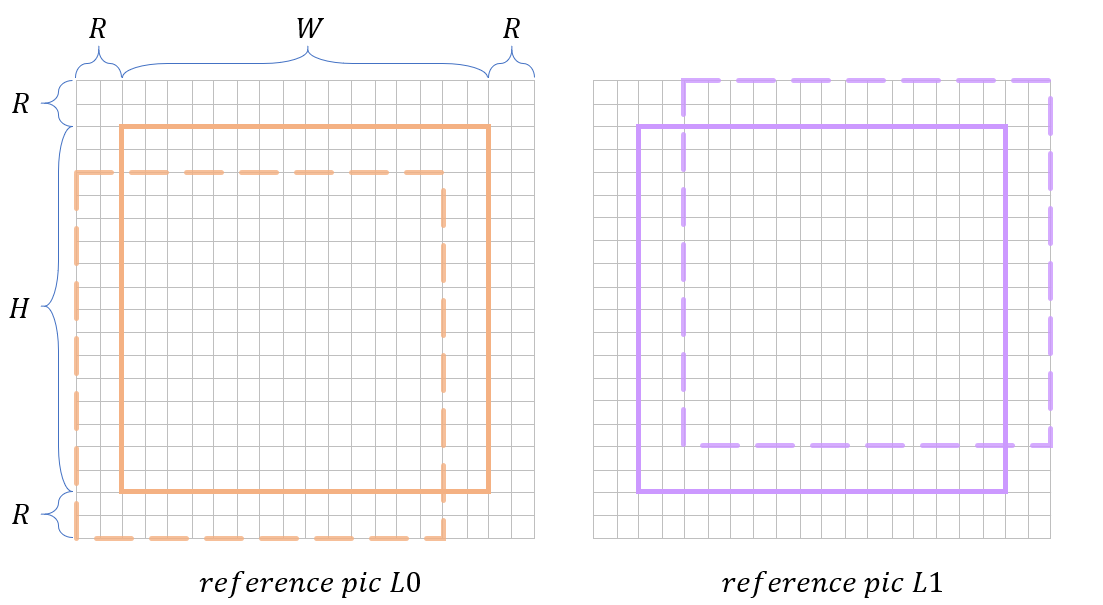
Prefetch predictions for reference pictures L0 and L1 according to original Merge candidate MV. DMVR search area is larger than block area, it is (W+2R) x (H+2R), where WxH is block size and R=2 is max searched offset. In order to avoid extra memory consumption and lower computation complexity 2-tap interpolation filter is used, instead of standard motion prediction 8-tap filter.
2. Initial check
Estimating initial prediction offset (0, 0) for SAD cost. Initial SAD value is lowered by weighting factor 0.75 to reduce the penalty of the uncertainty of DMVR refinement. If it is lower than threshold (W x H), DMVR search is skipped, selected offset is (0, 0).
3. Search for integer offset part
SAD is calculated for other integer offsets (-2..+2, -2..+2). Offset with minimum SAD is selected.
In order to reduce the amount of candidate block pairs, DMVR applies a mirroring property. The DMVR algorithm assumes translational motion. In Bi-prediction with one reference from past and one from future picture it’s likely that MVs require refinement with opposite directions.
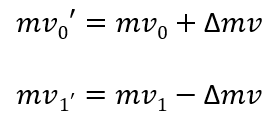
Max searched offset R=2, block could be moved up to (-2..+2, -2..+2), with integer offset there are 5 x 5 = 25 block candidates in each picture. That would require 25 x 25 = 625 checks for a full search. With mirroring property the amount of candidate pairs is reduced to 25.
4. Search for fractional offset part
Fractional part would require a lot more additional interpolations, buffering operations and SAD calculations. That’s why instead of a straight fractional offset search, VVC applies leveraging the integer SAD cost array in a 2D parametric error surface. Fractional search is used only when the integer offset is less than max R=2 for both sides.
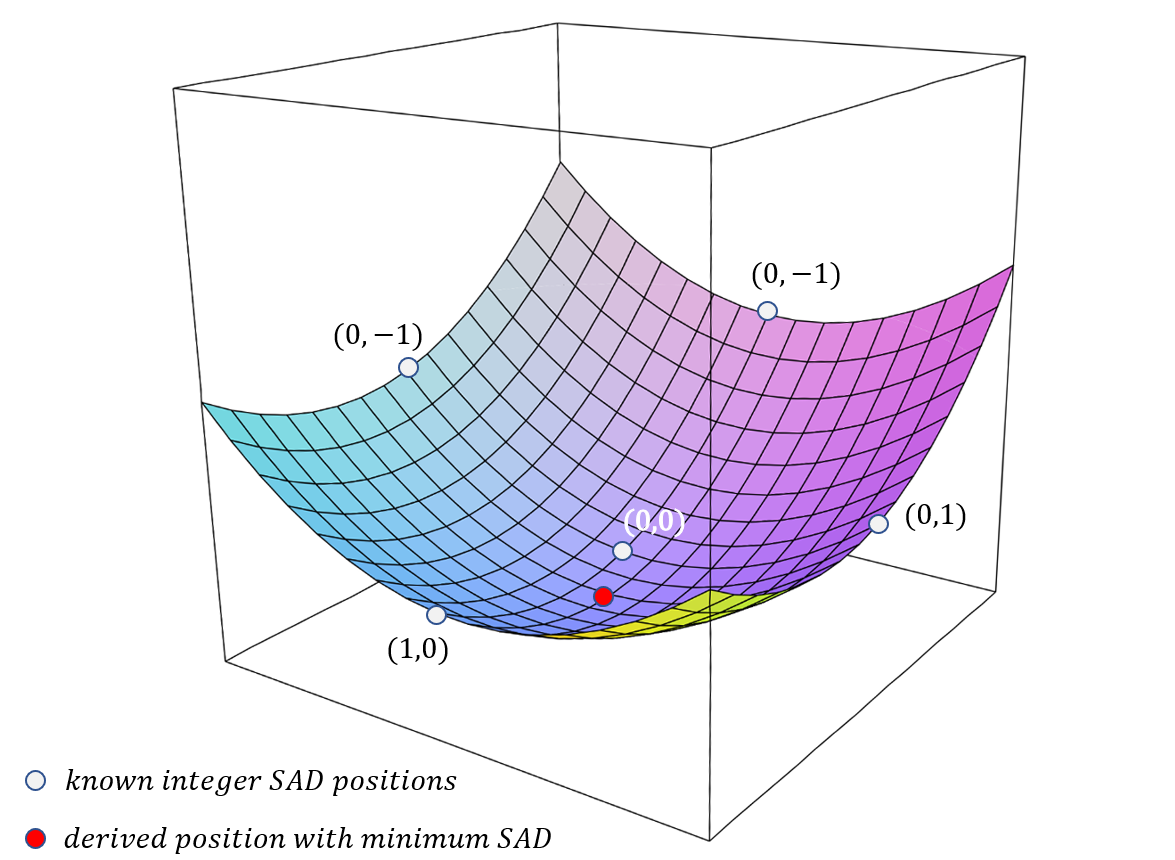
The center position cost and the costs at four neighboring positions from the center are used to fit a 2D parabolic error surface equation:
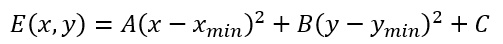
Solving the above equations by using the cost value of the five search points (0,0), (-1,0), (1,0), (0,-1), (0,1), the point (Xmin, Ymin) is computed as:
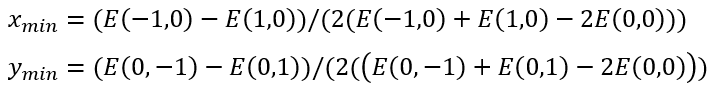
5. Final motion compensation
Motion compensation is done by refined MV (Figure 2) as a sum of integer and fractional parts. Standard 8-tap interpolation filter is used.
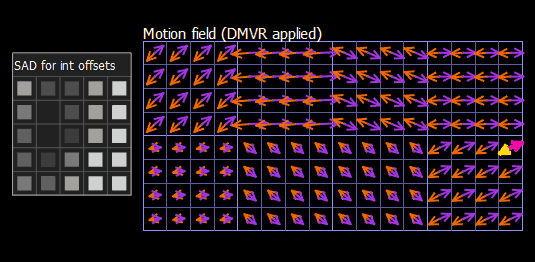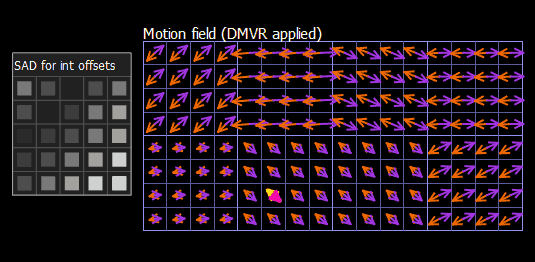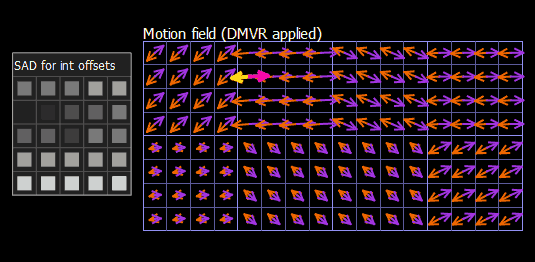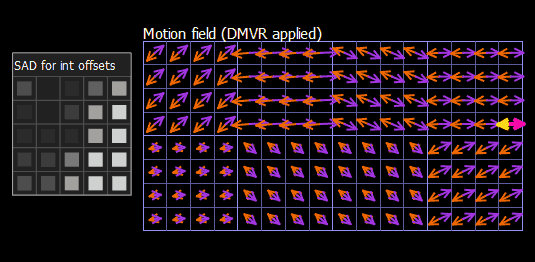
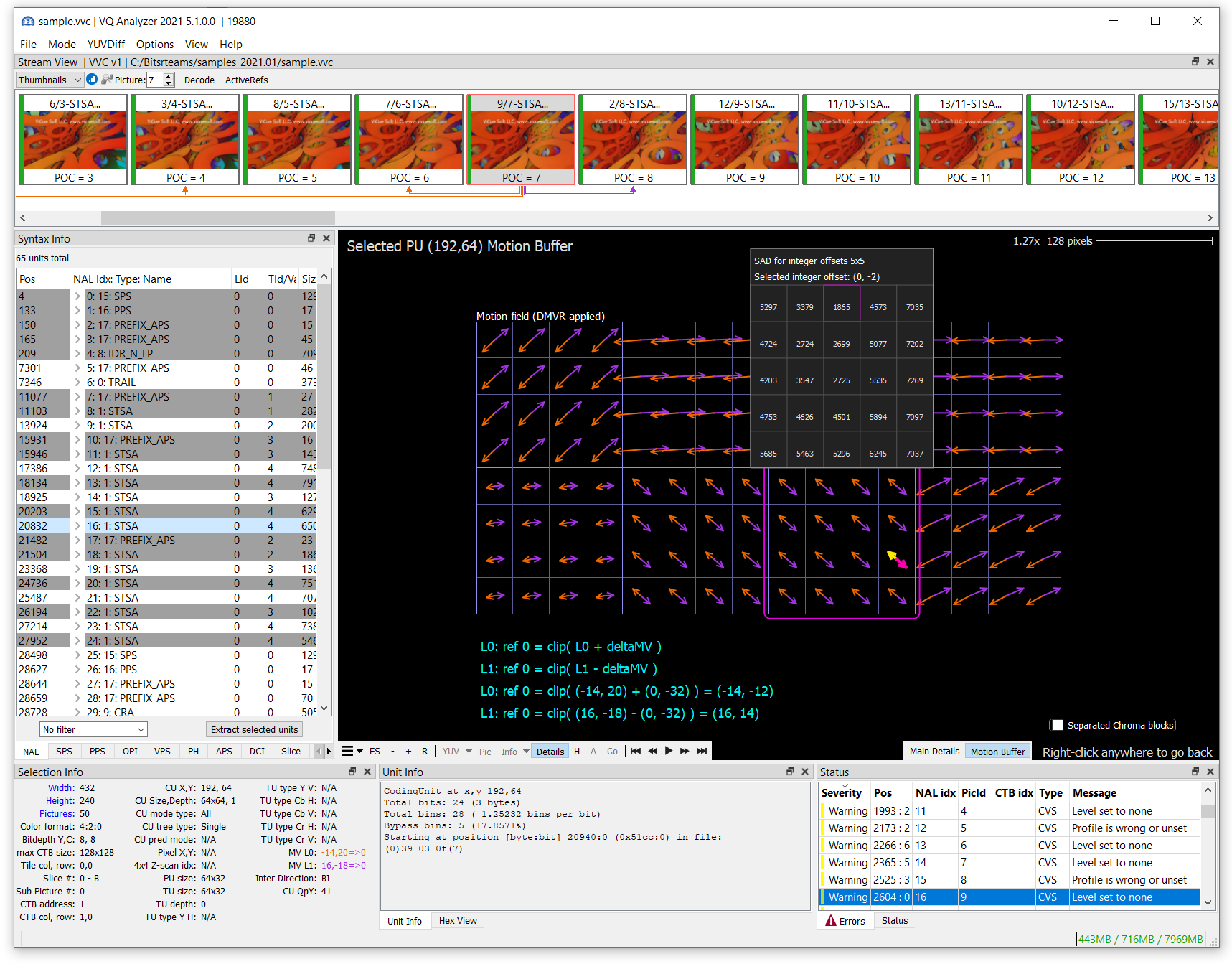
Let’s consider how block refinement works in VQ Analyzer. You can access a calculated SAD array for integer offsets, selected offset, refined mv and Δmv in the Details view of the Prediction block, using the Motion Buffer tab. On the screenshot below (Figure 6) we see a single prediction unit with homogeneous motion vectors L0 (-14,20) and L1 (16,-18), but each subblock has independent DMVR refinement. For the currently selected subblock, the best offset found is (0, -2) in pixel density.
Usage of refined vector
Reconstructed MV of the current block is used not only for its prediction, but also for prediction of future blocks and the deblocking loop filter process. In the case of block with DMVR, we have refined and original vectors.
Refined MV is used for: current block MCP and temporal MV prediction for future pictures.
Original MV is used for: deblocking process and spatial motion vector prediction for future CUs in the current picture.
DMVR limitations
To apply DMVR block, it should satisfy the following limitations:
- Prediction mode is Merge and block is bi-predicted (because of bilateral matching)
- CU has more than 128 luma samples
- CU height >= 8, CU width >= 8
- One reference in the past and one reference in the future, because of assumption of translational motion
- The POC differences are equal, to avoid MV scaling
- Both reference pictures are short-term reference pictures
- The following coding tools are not used: Affine, MMVD, BCW, Geo, CIIP, SbTMVP
This is all for today. In this article, we demonstrated how VQ Analyzer from ViCueSoft can visualize and display details for Merge mode with Decoder-Side Refinement tool in Versatile Video Codec. If you have any questions or comments, please feel free to write to us directly at info@vicuesoft.com.